
When you’re working with data in Python using Pandas, your dataset often comes with more information than you need. Perhaps your CSV contains extra metadata, there are duplicate fields, or you simply want to simplify your analysis. There you need to drop columns from Pandas dataframe.
Think of your DataFrame like a spreadsheet with too many columns. Before you can run meaningful analysis, you want to clean it up — just like clearing unnecessary columns from an Excel sheet. In Pandas, you do this with the drop() method (and a few other handy techniques).
In this guide, we’ll walk you through every method for removing columns from a Pandas DataFrame, explain the details behind each, and share real-world scenarios where this is relevant.
Remove Columns From Pandas DataFrame
There are multiple ways to drop columns from Pandas dataframe. Let’s go through each method:
The drop() Method in Pandas
The most common way to remove columns is with the drop() method.
Syntax
DataFrame.drop(
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors='raise'
)Parameters
- labels → The name(s) of rows or columns to remove.
- axis →
0means rows,1means columns. - columns → Shortcut for removing columns (recommended for clarity).
- inplace → If
True, modifies the original DataFrame. IfFalse(default), returns a new DataFrame. - errors → By default, Pandas will throw an error if you try to drop something that doesn’t exist. Use
errors="ignore"to avoid this.
For most column removal tasks, you’ll simply use:
df.drop(columns=["ColumnName"])
Drop a Single Column
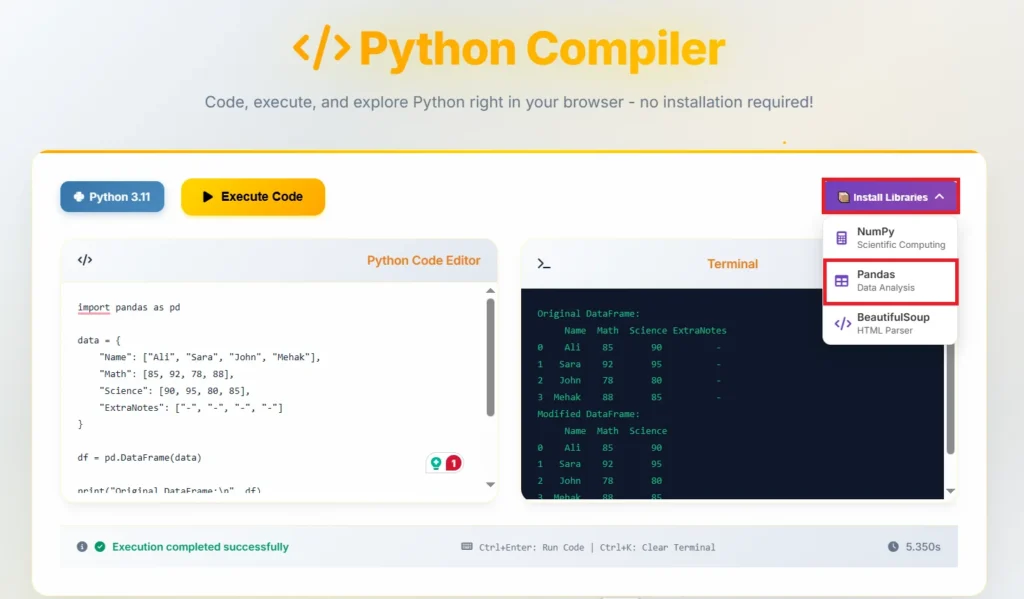
Example: removing "ExtraNotes" from a student grades dataset.
import pandas as pd
data = {
"Name": ["Ali", "Sara", "John", "Mehak"],
"Math": [85, 92, 78, 88],
"Science": [90, 95, 80, 85],
"ExtraNotes": ["-", "-", "-", "-"]
}
df = pd.DataFrame(data)
print("Original DataFrame:\n", df)
# Drop a single column
df = df.drop(columns=["ExtraNotes"])
print("\nModified DataFrame:\n", df)Output:
Original DataFrame:
Name Math Science ExtraNotes
0 Ali 85 90 -
1 Sara 92 95 -
2 John 78 80 -
3 Mehak 88 85 -
Modified DataFrame:
Name Math Science
0 Ali 85 90
1 Sara 92 95
2 John 78 80
3 Mehak 88 85Best practice: use the columns= parameter instead of axis=1 for readability.
Drop Multiple Columns
Need to drop more than one? Just pass a list of column names.
# Drop 'Math' and 'Science' df = df.drop(columns=["Math", "Science"])
This is helpful in machine learning pipelines where you want to remove multiple features at once.
Drop Columns by Index
Sometimes column names are messy or duplicated. In those cases, you can drop by index:
# Drop the first two columns by index df = df.drop(columns=df.columns[[0, 1]])
Tip: Always check column order with df.columns before using indices, since order can shift after merges or imports.
1. Using .pop()
Removes a column and returns it as a Series.
removed = df.pop("Math")
print("Removed column:\n", removed)Think of it like pulling a drawer out of a cabinet — you remove it, but you still keep the drawer itself.
2. Using del
Quickly deletes a column (in-place).
del df["Science"]
⚠️ Be careful: unlike drop(), there’s no undo — it modifies immediately.
3. Selecting a Subset of Columns
Instead of deleting, you can choose the columns you want to keep:
df = df[["Name", "Math"]]
This is often the cleanest approach when you know exactly which features you need.
Real-World Scenarios
Here’s where column dropping makes sense:
- Data cleaning: Removing
"Unnamed: 0"columns created during CSV export. - Text preprocessing: Dropping metadata like
"comments"or"URLs". - Machine learning prep: Excluding
"ID"or"Timestamp"columns that don’t add predictive value. - Performance optimization: Large logs with 100+ fields can be trimmed to the 10–15 you need.
Common Mistakes & Tips
- Forgetting to set
axis=1(orcolumns=) → Pandas defaults to rows, not columns. - Expecting the original DataFrame to change → Use
inplace=Trueor reassign (df = df.drop(...)). - Dropping non-existent columns → Use
errors="ignore"if you’re not sure. - Overusing
inplace=True→ Sometimes keeping both original and modified versions helps avoid mistakes.
FAQs: Pandas Drop Column
Q1: What’s the difference between drop() and pop()?
drop()→ Removes multiple columns, returns DataFrame.pop()→ Removes one column, returns Series.
Q2: Can I drop rows with drop()?
Yes — just set axis=0 or use the index= parameter.
Q3: Which is faster, drop() or del?del is slightly faster (since it works in-place), but drop() is safer and more flexible.
Q4: How do I drop duplicate columns?
You can use:
df = df.loc[:, ~df.columns.duplicated()]
Q5: How do I drop columns with missing values?
df = df.dropna(axis=1)
This removes all columns with at least one NaN.
Conclusion
Dropping columns in Pandas is a fundamental data-cleaning skill. Whether you use drop(), pop(), del, or column selection, the goal is the same: streamline your DataFrame for cleaner analysis and faster processing.
Key takeaways:
- Use
drop(columns=...)for clarity. - Be mindful of
inplace=True. - Explore
pop()if you want the removed column separately. - Always think in terms of what data you truly need.
Ready to try it yourself? Experiment with dropping columns right now in our Online Python Compiler — practice by creating a sample DataFrame and cleaning it up.
For more interesting articles, follow our Python tutorial series by SyntaxScenarios.