Have you ever wondered how websites are organized? Just like a postal address helps you find a house, a URL helps your browser locate a website. But what if you only need the neighborhood (root domain) or the building (subdomain)? In this article, we’ll explore all possible ways to extract the root domain and subdomain from a URL using Python.
Understanding URLs: The Postal Address of the Internet
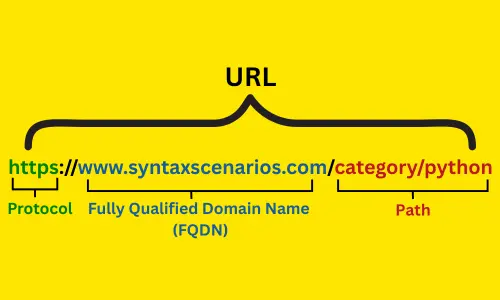
Think of a URL as a postal address for a website. For example:
https://syntaxscenarios.com/category/python
Here’s what each part means:
https: This is the protocol. Think of it as the mode of transportation (like a car or bike).syntaxscenarios.com: This is the domain. It’s like the full address./category/python: This is the path. It’s like the specific room in the building.
Our goal is to extract the neighborhood (root domain) and the building (subdomain) from this address.
What Are Root Domain and Subdomain?

Let’s break it down:
Root Domain
This is the main part of the address. For example, in
www.syntaxscenarios.com
, the root domain is syntaxscenarios.com. Think of it as the neighborhood.
Subdomain
This is an optional part that comes before the root domain. For example, in
www.syntaxscenarios.com
, the subdomain is www. And if the URL was:
https://blog.syntaxscenarios.com
, the subdomain would be blog. Think of it as the specific building in the neighborhood.
Why Extract Root and Sub Domains?
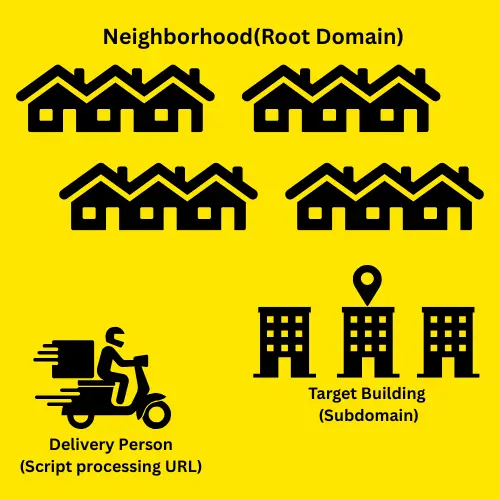
Imagine you’re a delivery person. You need to know the neighborhood (root domain) to find the general area and the building (subdomain) to deliver the package to the right place. Similarly, in programming, extracting these parts helps in:
- Analyzing website traffic.
- Building web scrapers.
- Organizing data for SEO tools.
Methods to Get Root and Sub Domain From URL in Python
Below are the possible ways to get root and subdomain from URL in Python. Let’s go step by step.
Method 1: Using urlparse (The Basic Street Sign)
The urlparse module is part of Python’s standard library. It’s like a basic street sign that tells you the main address, but you have to figure out the subdomain yourself.
Syntax:
parsed_url = urlparse('url')urlparse('url'): Parses the given URL and returns its components.
Example:
from urllib.parse import urlparse
url = "https://www.syntaxscenarios.com/category/python"
parsed_url = urlparse(url)
host = parsed_url.hostname # 'www.syntaxscenarios.com'
parts = host.split('.')
subdomain = ".".join(parts[:-2]) # 'www'
root_domain = ".".join(parts[-2:]) # 'syntaxscenarios.com'
print("Subdomain:", subdomain)
print("Root Domain:", root_domain)Output:
Subdomain: www Root Domain: syntaxscenarios.com
Limitations:
- It may struggle with complex domains like .co.uk.
- Requires manual adjustments for multi-level subdomains.
Method 2: Using tldextract (The Smart Address Book)
Think of tldextract as a smart address book. It knows exactly which part of the website is the root domain and which is the subdomain.
Syntax:
ext = extract('url')extract('url'): Breaks the URL into subdomain, domain, and suffix (TLD).
Example:
- Install the library:
pip install tldextract
- Use the library in your code:
import tldextract
url = "https://www.syntaxscenarios.com/category/python"
extracted = tldextract.extract(url)
subdomain = extracted.subdomain # 'www'
root_domain = f"{extracted.domain}.{extracted.suffix}" # 'syntaxscenarios.com'
print("Subdomain:", subdomain)
print("Root Domain:", root_domain)Output:
Subdomain: www Root Domain: syntaxscenarios.com
Why Use tldextract?
- It’s accurate and handles complex domains like .co.uk or .gov.in.
- It’s beginner-friendly and requires minimal code.
Method 3: Using publicsuffixlist (The Detailed Map)
This method uses the Public Suffix List to correctly identify TLDs. Think of it as a detailed map that includes every tiny detail.
Example:
- Install the library:
pip install publicsuffixlist
2. Use the library in your code:
from urllib.parse import urlparse
from publicsuffixlist import PublicSuffixList
psl = PublicSuffixList()
url = "https://www.syntaxscenarios.com/category/python"
parsed_url = urlparse(url)
host = parsed_url.hostname # 'www.syntaxscenarios.com'
tld = psl.publicsuffix(host) # 'com'
parts = host.rsplit("." + tld, 1)[0].split('.')
subdomain = ".".join(parts[:-1]) # 'www'
root_domain = parts[-1] # 'syntaxscenarios'
print("Subdomain:", subdomain)
print("Root Domain:", root_domain)
print("TLD:", tld)Output:
Subdomain: www Root Domain: syntaxscenarios TLD: com
Why Use publicsuffixlist?
- It handles multi-part TLDs correctly.
- Requires an updated suffix list for accuracy.
Method 4: Using Regex (The Detective Approach)
Think of regex as a detective with a magnifying glass. It looks for patterns in the URL and extracts the root and subdomains.
Syntax:
match = re.match(r"regex_pattern", url)
re.match(r"regex_pattern", url): Tries to match theurlstring from the beginning using the specified regular expression pattern.r"regex_pattern": A raw string containing the regex pattern to search for.match: Stores the matched object if a match is found; otherwise, it returnsNone.
Example:
import re
url = "https://www.syntaxscenarios.com/category/python"
match = re.match(r"https?://(?:www\.)?(([^.]+)\.([^.]+\.[a-z]+))", url)
if match:
subdomain = match.group(2) # 'www'
root_domain = match.group(3).split('.')[0] # 'syntaxscenarios'
print("Subdomain:", subdomain)
print("Root Domain:", root_domain)Output:
Subdomain: www Root Domain: syntaxscenarios
Limitations:
- It may break on complex URLs.
- Not always accurate for multi-level subdomains.
Handling Complex Addresses
Now the real challenge lies in handling multi-level subdomains (e.g., blog.syntaxscenarios.com) or country-code domains (e.g., syntaxscenarios.co.uk) which are not just simple TLDs. Here is a beginner-friendly approach to get the root and the sub domain from complex URL:
Steps:
- Use
tldextractfor accurate extraction. - Add custom logic to handle multi-level subdomains.
Example:
import tldextract
def extract_domain_info(url):
extracted = tldextract.extract(url)
root_domain = f"{extracted.domain}.{extracted.suffix}" # Neighborhood
subdomain = extracted.subdomain # Building
# Handle multi-level subdomains
if subdomain.count('.') > 0:
subdomain_parts = subdomain.split('.')
subdomain = '.'.join(subdomain_parts) # Keep all subdomain levels
return root_domain, subdomain
url = "https://syntaxscenarios.co.uk/"
root_domain, subdomain = extract_domain_info(url)
print("Root Domain:", root_domain)
print("Subdomain:", subdomain) # Output: (empty, as there is no subdomain)Output:
Root Domain: syntaxscenarios.co.uk Subdomain:
Why This Approach?
- It ensures accuracy for complex addresses.
- It retains all levels of subdomains for further analysis.
Which Method Should You Use?
| Method | Best For | Accuracy | Handles Multi-level TLDs? | Requires External Library? |
tldextract | Real-world domains | ✅ High | Yes | Yes (tldextract) |
urllib.parse | Quick, simple domains | ⚠️ Medium | No | No |
publicsuffixlist | Multi-level TLDs | 👍 Very Good | Yes | Yes (publicsuffixlist) |
| Regex | Fast, simple domains | ⚠️ Low | No | No |
Final Thoughts
Extracting the root domain and subdomain from a URL is important for tasks like web scraping and SEO. While there are many ways to do this like urllib.parse, publicsuffixlist, and regex, tldextract is the easiest and most accurate, especially for tricky domains like .co.uk. For more complex cases, you can add custom logic to tldextract to handle multi-level subdomains. These methods will help you work with URLs easily whether you’re new to coding or an expert.
For more engaging and informative articles on Python, check out our Python tutorial series at Syntax Scenarios.