Learn how to combine multiple CSV files into a single file in Python, using different methods like append(), concat(), and merge() with real world examples, visuals, and easy code snippets.
Combine Multiple CSV Files – A Real-world Analogy
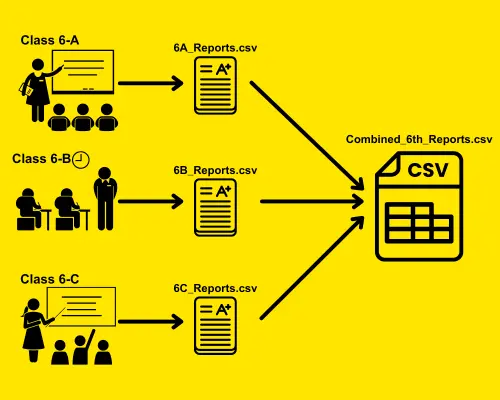
Imagine you’re a teacher handling three different classes, each with around 30 students. At the end of the term, each class sends you their grades in separate CSV files, and you need to merge and consolidate all these CSV files into one comprehensive report. Manually copying and pasting the data would be not only slow but also inclined to errors, especially when dealing with such a large number of students.
Pre-requisite: Install Pandas
Before you start, make sure you have installed the Pandas library, which simplifies handling CSV files. To install pandas, open your terminal or command prompt and run:
pip install pandas
List Your CSV Files
The first step in joining multiple files is to identify the CSV files you want to merge. You can use Python’s glob module to match file patterns and list all the CSV files in the directory. If you want to merge all the files within a directory, you can use the following command:
import glob
# Find all CSV files in the current directory
csv_files = glob.glob('*.csv')
print(csv_files) # Prints the list of CSV filesA Practical Example: Merging Bakery Reports
Imagine you’re the owner of multiple bakeries. Each branch has its own daily report (e.g. daily sales, customer visits, and inventory reports), and you want to combine all these reports to get a complete view of your bakery’s performance. By listing the CSV files (reports) from each branch, you’re preparing to bring all that data into one single, easy-to-analyze document.
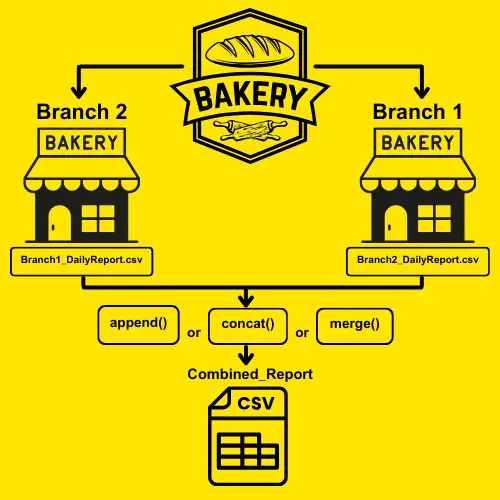
Combine Multiple CSV Files in Python
Method 1: Use append() Method
The append() method joins data from one DataFrame (or CSV file) with another by stacking them on top of each other.
Syntax
ther_dataframe: The DataFrame or Series to append.ignore_index: IfTrue, the resulting DataFrame will have a new, continuous index. By default, it’sFalse, so the original index labels are kept.
new_dataframe = original_dataframe.append(other_dataframe, ignore_index=False)
Code
An empty DataFrame is created in the following code to store join data from multiple CSV files. The program defines a list of CSV file names, which are daily reports from different branches. It then uses a loop to go through each file in the list, reading the data from the CSV file into a temporary DataFrame. This data is printed to show its content, and then it is added (or appended) to the main combined_data DataFrame. After all files are processed and combined, the final DataFrame is displayed, showing the merged data from all branches. Additionally, the combined data is saved into a new CSV file named combined_bakery_report.csv for future use.
import pandas as pd
# Create an empty DataFrame to hold combined data
combined_data = pd.DataFrame()
# List of CSV files to be combined
csv_file_list = ["Branch1_DailyReport.csv", "Branch2_DailyReport.csv", "Branch3_DailyReport.csv"]
# Append data from each CSV file into the combined DataFrame
for csv_file in csv_file_list:
print(f"Reading: {csv_file}") # Print the name of the CSV file being read
data_chunk = pd.read_csv(csv_file) # Reading the CSV file
print(data_chunk) # Print the content of the DataFrame
combined_data = combined_data.append(data_chunk, ignore_index=True) # Adding the data to the combined DataFrame
# Display the final combined DataFrame
print("\nCombined DataFrame:")
print(combined_data)
# Save the combined data to a new CSV file (optional)
combined_data.to_csv('combined_bakery_report.csv', index=False)Output
Reading: Branch1_DailyReport.csv
Branch Date Sales Customers
0 Bakery 1 10/10/2024 1500 200
Reading: Branch2_DailyReport.csv
Branch Date Sales Customers
0 Bakery 2 10/10/2024 1700 230
Reading: Branch3_DailyReport.csv
Branch Date Sales Customers
0 Bakery 3 10/10/2024 1600 210
Combined DataFrame:
Branch Date Sales Customers
0 Bakery 1 10/10/2024 1500 200
1 Bakery 2 10/10/2024 1700 230
2 Bakery 3 10/10/2024 1600 210Why append() May Not Work in Your Code?
If you see the error 'DataFrame' object has no attribute 'append', it means you’re using Pandas version 2.0.0 or higher, where the append() method was removed.
Checking Your Pandas Version
To check your current Pandas version, simply run this code:
import pandas as pd print(pd.__version__)
Output
2.2.2
Still, Want to Use append()?
However, if you still want to use append(), you can install an older version of Pandas (before version 2.0.0). To do this, simply run:
pip install pandas==1.5.3
Now when you try using the append() method, it will not cause an error.
Instead of append(), you can easily switch to Method 2, which uses pd.concat() for similar results.
Method 2: Use concat()
The concat() method merges multiple DataFrames either by rows or columns, depending on the axis.
Syntax
objs: A list or dictionary of pandas objects (e.g., DataFrames) you want to concatenate.axis: The axis along which to concatenate.axis=0concatenates along rows, whileaxis=1concatenates along columns.ignore_index: IfTrue, the resulting DataFrame will have a new, continuous index.
result = pd.concat(objs, axis=0, ignore_index=False)
Code
In the following code, an empty list called data_frames is created to hold individual DataFrames. A list of CSV file names, representing daily reports from different branches, is defined. The program loops through each file in the list, reads the data from the CSV file into a temporary DataFrame (data_chunk), and prints the content of the file for verification. Then, this DataFrame is added to the data_frames list.
After all files have been processed and added to the list, the pd.concat() method is used to join all DataFrames from the list into a single DataFrame called combined_data. The ignore_index=True option ensures that the indices are reset in the resulting DataFrame. Finally, the combined DataFrame is displayed, and it is saved to a new CSV file named combined_bakery_report.csv.
import pandas as pd
# Create an empty list to hold DataFrames
data_frames = []
# List of CSV files to be combined
csv_file_list = ["Branch1_DailyReport.csv", "Branch2_DailyReport.csv", "Branch3_DailyReport.csv"]
# Read each CSV file, print its name, content, and add it to the list
for csv_file in csv_file_list:
print(f"Reading: {csv_file}") # Print the name of the CSV file being read
data_chunk = pd.read_csv(csv_file) # Reading the CSV file
print(data_chunk) # Print the content of the DataFrame
data_frames.append(data_chunk) # Adding the DataFrame to the list
# Concatenate all DataFrames in the list into a single DataFrame
combined_data = pd.concat(data_frames, ignore_index=True) # Merging all DataFrames into one
# Display the final combined DataFrame
print("\nCombined DataFrame:")
print(combined_data)
# Save the combined data to a new CSV file
combined_data.to_csv('combined_bakery_report.csv', index=False)Output
Reading: Branch1_DailyReport.csv
Branch Date Sales Customers
0 Bakery 1 10/10/2024 1500 200
Reading: Branch2_DailyReport.csv
Branch Date Sales Customers
0 Bakery 2 10/10/2024 1700 230
Reading: Branch3_DailyReport.csv
Branch Date Sales Customers
0 Bakery 3 10/10/2024 1600 210
Combined DataFrame:
Branch Date Sales Customers
0 Bakery 1 10/10/2024 1500 200
1 Bakery 2 10/10/2024 1700 230
2 Bakery 3 10/10/2024 1600 210Method 3: Use merge()
The merge() method connects two DataFrames using a common key, such as a product name or date.
Syntax
df1,df2: The DataFrames to be merged.how: The type of join (e.g.,'inner','outer','left','right'). The default is'inner'.on: The name of the common column(s) to join on. If not specified, it tries to join on all common columns.
merged_dataframe = df1.merge(df2, how='type_of_join', on='column_name')
Code
The merge() function here combines the two DataFrames based on common columns. This function performs an “outer” join, meaning it will include all the data from both DataFrames, even if there are missing matches between them (such as different dates or product names). After merging, the resulting merged_sales_data DataFrame is printed to show the combined data from both branches. Finally, the merged data is saved into a new CSV file called Merged_SalesData.csv.
import pandas as pd
# Read the CSV files into DataFrames
print("Reading: Branch1_SalesData.csv") # Print the name of the first CSV file being read
sales_data_1 = pd.read_csv('Branch1_SalesData.csv') # Reading the first CSV file
print(sales_data_1) # Print the content of the first DataFrame
print("\nReading: Branch2_SalesData.csv") # Print the name of the second CSV file being read
sales_data_2 = pd.read_csv('Branch2_SalesData.csv') # Reading the second CSV file
print(sales_data_2) # Print the content of the second DataFrame
# Merge the two DataFrames based on common columns (e.g., product name or date)
# Joining data on matching columns, using an 'outer' join to include all data
merged_sales_data = sales_data_1.merge(sales_data_2, how='outer')
# Print the merged DataFrame
print("\nMerged Sales Data:")
print(merged_sales_data)
# Save the merged data to a new CSV file
merged_sales_data.to_csv('Merged_SalesData.csv', index=False)Output
Reading: Branch1_SalesData.csv
Date Product Sales_Branch_1
0 2024-10-12 Croissant 50
1 2024-10-12 Donut 40
2 2024-10-13 Croissant 60
Reading: Branch2_SalesData.csv
Date Product Sales_Branch_2
0 12/10/2024 Croissant 55
1 13/10/2024 Croissant 45
2 13/10/2024 Bagel 30
Merged Sales Data:
Date Product Sales_Branch_1 Sales_Branch_2
0 12/10/2024 Croissant NaN 55.0
1 13/10/2024 Bagel NaN 30.0
2 13/10/2024 Croissant NaN 45.0
3 2024-10-12 Croissant 50.0 NaN
4 2024-10-12 Donut 40.0 NaN
5 2024-10-13 Croissant 60.0 NaNDifference Between append(), merge(), and concat()
All these three methods can be used to merge multiple tables into one. However there are some minor differences among all.
| Method | Working | Parameters | Axis Control | Join Type Support |
append() | Adds rows of data from one DataFrame to another. | other (DataFrame), ignore_index (bool) | Not explicitly, always adds along rows. | No joins, just appends rows. |
merge() | Combines two DataFrames based on common columns or indices. | how (type of join), on (column name), left_on, right_on | No explicit axis control, based on matching columns. | Keeps index from both DataFrames unless specified. |
concat() | Concatenates DataFrames along a particular axis (rows or columns). | objs (list of DataFrames), axis=0 (rows) or axis=1 (columns), ignore_index (bool) | Yes, axis=0 (rows) or axis=1 (columns). | Can reset index with ignore_index=True. |
Tips for Merging CSVs
You might encounter some challenges when working with CSV files. Here are a few tips that can help make the process smoother when you unify several CSV files into one using Python:
Tip 1: Handling Inconsistent Headers
When merging CSV files with different headers, some columns might be missing or have different names. Using the concat() method with sort=False ensures all columns are included, even if some data is missing. If a column is missing in one file, the empty cells will be filled with “NaN” (Not a Number), keeping the data organized.
The code reads multiple CSV files, merges them into one DataFrame while handling missing columns, and saves the data into a new CSV file.
# Create an empty DataFrame to hold the combined data
merged_data = pd.DataFrame()
# Loop through each CSV file and append its content to the merged_data DataFrame
for file in csv_files:
current_data = pd.read_csv(file)
merged_data = pd.concat([merged_data, current_data], ignore_index=True, sort=False)
# Save the combined data to a new CSV file
merged_data.to_csv('consolidated_sales_data.csv', index=False)- NaN (Not a Number): it is used in data handling to represent missing or undefined data). You can filter NaN in Python using several ways.
Tip 2: Handling Large Data with Chunks
If you are working with very large CSV files that might not fit into memory, you can use the chunksize parameter to read and merge the files into smaller pieces. This helps prevent your program from running out of memory.
The code reads large CSV files in chunks, joins them, and saves the result as a single file without using too much memory.
chunk_size = 1000 # Number of rows per chunk
combined_chunks = pd.DataFrame()
for file in csv_files:
for chunk in pd.read_csv(file, chunksize=chunk_size):
combined_chunks = pd.concat([combined_chunks, chunk], ignore_index=True)
combined_chunks.to_csv('combined_large_sales_data.csv', index=False)When do We Need to Integrate Multiple CSV Files?
Here are some specific real-world scenarios where combining multiple CSV files into one in Python is useful:
- Sales Data from Multiple Branches: A company with multiple branches might store each branch’s sales data in separate CSV files. To analyze total sales or compare performance across branches, you would need to join all the CSV files into one.
- Survey Results from Different Time Periods: When conducting surveys at different times (e.g., quarterly), each period’s results might be stored in separate CSV files. Combining these files helps analyze overall trends over time.
- Combining Training Data from Different Sources: In machine learning, you might collect data from multiple sources (e.g., different datasets, APIs, or systems). Merging these CSV files creates a comprehensive training set, improving the model’s generalization.
- Financial Reports from Different Departments: If different departments of a company (HR, Marketing, IT) maintain separate financial reports, combining these CSV files create a unified report for company-wide financial analysis.
- Merging Customer Data: If customer information (e.g., profiles, purchases) is stored in different CSVs by product or region, merging them creates a single dataset for customer analysis, segmentation, or targeted marketing.
Conclusion
With Python and pandas, you’ve learned how to easily combine numerous CSV files into one, which saves you from the trouble of manually merging data. Python makes it simple to bring all your data together, whether you’re working with bakery sales, student grades, or email lists. By using methods like merge(), concat(), append(), and handling large files in chunks, you can manage big or messy data. Next time you deal with data from various CSVs, you can spend less time on manual work and more time on what matters most!