
Imagine you’re working on a Python project and need to clean up a dataset. The problem? Duplicate entries. It’s a common issue, and duplicates can really mess with your data and create confusion during data analysis. In this article, we’ll walk you through simple ways to check for duplicates in a Python list. Plus, we’ll explore different methods so you can choose the best one for your needs.
What are Duplicates in a List?
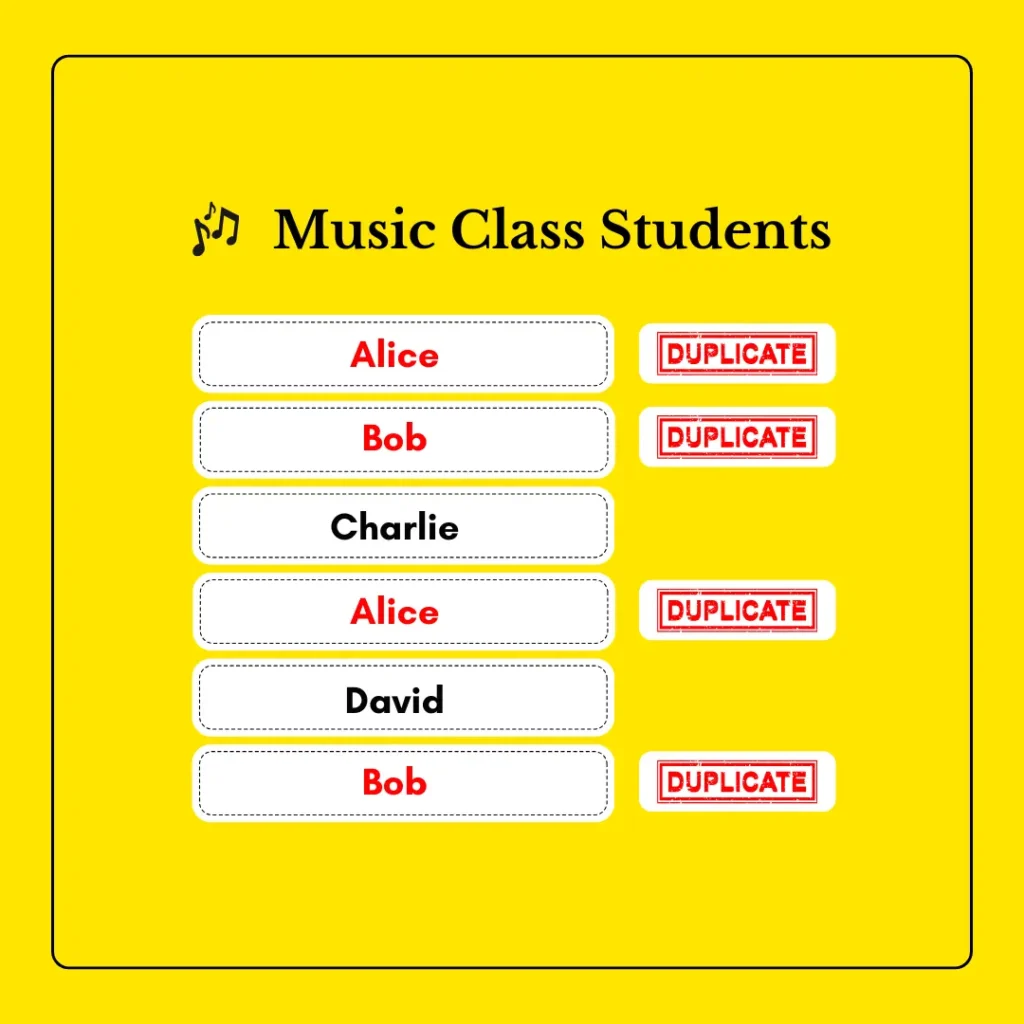
Imagine you have a list of students who signed up for a music class, but some accidentally registered twice! In the same way, a duplicate in a list means that a value appears more than once.
Example Code
In this example, “Alice” and “Bob” are duplicates because they appear twice in the students list.
students = ["Alice", "Bob", "Charlie", "Alice", "David", "Bob"]
Different Methods to Find Duplicate Items in a Python List
Method 1: Using Nested Loops
A simple but inefficient way to check for duplicates in a Python list is using nested loops. The first loop selects an item, and the second loop compares it with every other item in the list.
Example Code
- In the example below, we have a list of email addresses
emailswith some duplicates. - First, we create an empty list
duplicatesto store repeated emails. - The outer for loop
igoes through each email in the list. - The inner for loop
jcompares the current emailemails[i]with each email that comes after it. - If
emails[i] == emails[j]and the email hasn’t already been added toduplicates, we add it to the list. - Finally, we print the list
duplicates, which contains all the repeated emails.
# List of emails with some duplicates
emails = ["john@example.com", "jane@example.com", "john@example.com", "doe@example.com", "jane@example.com"]
# Empty list to store duplicates
duplicates = []
# Outer for loop to check each email
for i in range(len(emails)):
# Inner for loop to compare with subsequent emails
for j in range(i + 1, len(emails)):
# Condition to check if a duplicate is found and not already in duplicates list
if emails[i] == emails[j] and emails[i] not in duplicates:
# Add duplicate to list
duplicates.append(emails[i])
# Print duplicates
print(duplicates)Output
['john@example.com', 'jane@example.com']
Method 2: Using a Set
A set in Python is a collection of unique, unordered items. When you convert a list into a set, it automatically removes any duplicates. By comparing the set to the original list, you can quickly identify duplicates. However, keep in mind that this method may change the order of the elements in the list.
Example Code
- In this code, the list
colourscontains some repeated colours. - First, we create an empty set
seento keep track of the colours we’ve already checked. - We then initialize another empty set
duplicatesto store the colours that appear more than once. - The for loop
colouriterates through each colour in the listcolours. - For each colour, the code checks if it has already been seen.
- If it has, it means the colour is a duplicate, so we add it to the
duplicatesset. - If it hasn’t been seen, we add it to the
seenset. - Lastly, we convert the
duplicatesset to a list and print it to display all the repeated colours.
# List of colours with some repeats
colours = ["red", "blue", "green", "red", "yellow", "blue", "pink"]
# Set to track seen colours
seen = set()
# Set to store duplicates
duplicates = set()
# Loop through colours
for colour in colours:
# If the color is seen, add it to duplicates; otherwise, add it to seen
if colour in seen:
duplicates.add(colour)
else:
seen.add(colour)
# Print duplicates as a list
print(list(duplicates))Output
['red', 'blue']
Method 3: Using List Comprehension
List comprehension provides a compact way to scan through a list and identify duplicates. It’s perfect for small to medium-sized lists, or if you prefer a simple, one-liner solution that’s quick to implement.
Example Code
- Here, the list
integerscontains some repeated numbers. - We use list comprehension with
enumerate(integers)to loop through each item in the list. - The
enumeratefunction provides both the index and the value of each item. integers[:index]slices the list to include all the elements before the current one.- If the current item is found in that slice, it means it’s a duplicate, so it’s get added to the
duplicateslist. - Finally, the
duplicateslist is printed.
# List of numbers with some duplicates integers = [1, 2, 3, 4, 4, 5, 6, 6] # List comprehension to find duplicates duplicates = [item for index, item in enumerate(integers) if item in integers[:index]] # Print the duplicates found print(duplicates)
Output
[4, 6]
Method 4: Using collections.Counter with List Comprehension
The Counter class from the collections module is another powerful option for checking duplicates in a list. When combined with list comprehension, it becomes particularly useful for managing larger datasets, while list comprehension alone works well for smaller ones.
Example Code
- In the following example code, we first import the
Counterclass from thecollectionsmodule. - The list
fruitscontains the names of fruits, including some duplicates. - The
Countercreates a dictionary where the keys are the fruits, and the values represent how many times each fruit appears in the list. - Next, we use list comprehension to loop through the counted items, checking if the frequency is greater than 1.
- If the frequency is greater than 1, it means the fruit is a duplicate, so it gets added to the
duplicateslist. - The
duplicateslist is then printed to show the repeated fruits.
from collections import Counter # List of fruits with duplicates fruits = ["apple", "banana", "cherry", "apple", "banana", "orange"] # Count occurrences of each fruit count = Counter(fruits) # List comprehension to find fruits that appear more than once duplicates = [fruit for fruit, freq in count.items() if freq > 1] # Print duplicates print(duplicates)
Output
['apple', 'banana']
Bonus: How to Remove Duplicates from a List?
Once you’ve found duplicates, you may want to remove them. The simplest way to do this is by using set().
Example Code
In this example, the list students is first converted into a set to remove duplicates and then converted back into a list to maintain the list format. The resulting list is stored in unique_students and printed at the end.
students = ["Alice", "Bob", "Charlie", "Alice", "David", "Bob"] unique_students = list(set(students)) print(unique_students)
Output
['Bob', 'David', 'Charlie', 'Alice']
As you can see, using set() removes duplicates but also changes the order of elements. If you want to preserve the original order, you can use dict.fromkeys(students). Here’s how you can do it:
students = ["Alice", "Bob", "Charlie", "Alice", "David", "Bob"] unique_students = list(dict.fromkeys(students)) print(unique_students)
Output
['Alice', 'Bob', 'Charlie', 'David']
Conclusion
And there you have it! You now have a variety of methods in your Python toolbox to check for duplicates in a list. Each approach has its own strengths, allowing you to choose the one that suits your needs best. Whether you go with list comprehension, nested loops, or Counter, you’ll be able to tackle duplicates easily.
Remember, checking for duplicates isn’t just about cleaning up your lists; it’s about making your code cleaner and error-free. So, the next time you run into a list full of duplicates, you’ll have the right tools to handle it without a hitch.
For more easy-to-follow Python tutorials, don’t miss our Python Series at Syntax Scenarios!